云服务器系统更新后出现 I/O error
2025-12-23 server云服务器上的 Arch Linux 在最近一次系统更新并手动重启后 dockerd 无法启动,journalctl 看到服务日志中的报错为
Main process exited, code=dumped, status=11/SEGV。
于是将服务器上的/usr/bin/dockerd与本地文件及官方包中的文件进行对比,发现文件大小均一致,但计算出的 SHA256 只有服务器上的文件不一致,说明文件已损坏。
进一步使用 journalctl 查看全量系统日志,发现大量kernel: I/O error,推测是系统更新过程中文件写入出现问题,最终导致文件损坏。
环境
腾讯云轻量应用服务器,4核CPU,4GB内存,80GB SSD云硬盘。
初始化时使用官方的 CentOS 7.6 系统镜像,随后使用 vps2arch 脚本转换为 Arch Linux。
创建时间为 2021 年初,至今大约每隔 1-2 个月进行一次系统更新,且在更新完毕后均会手动重启系统。
问题
2025-12-20 周六凌晨执行 pacman -Syu 更新完系统后,照常手动重启服务器,重启后发现 dockerd 无法启动,执行 systemctl status docker 查看服务状态:
× docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; preset: disabled)
Active: failed (Result: core-dump) since Sat 2025-12-20 03:22:49 CST; 10s ago
Duration: 31.211s
Invocation: 2869070a2a8f47b6a3684a9e59f04290
TriggeredBy: × docker.socket
Docs: https://docs.docker.com
Process: 1615 ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock (code=dumped, signal=SEGV)
Main PID: 1615 (code=dumped, signal=SEGV)
Mem peak: 9.2M
CPU: 68ms
Dec 20 03:22:47 tencent systemd[1]: docker.service: Failed with result 'core-dump'.
Dec 20 03:22:47 tencent systemd[1]: Failed to start Docker Application Container Engine.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Start request repeated too quickly.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Failed with result 'core-dump'.
Dec 20 03:22:49 tencent systemd[1]: Failed to start Docker Application Container Engine.
于是执行 journalctl -r -u docker 查看服务日志中的详细报错:
Dec 20 03:22:49 tencent systemd[1]: Failed to start Docker Application Container Engine.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Failed with result 'core-dump'.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Start request repeated too quickly.
Dec 20 03:22:49 tencent systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.
Dec 20 03:22:47 tencent systemd[1]: Failed to start Docker Application Container Engine.
Dec 20 03:22:47 tencent systemd[1]: docker.service: Failed with result 'core-dump'.
Dec 20 03:22:47 tencent systemd[1]: docker.service: Main process exited, code=dumped, status=11/SEGV
Dec 20 03:22:47 tencent systemd-coredump[1617]: [🡕] Process 1615 (dockerd) of user 0 dumped core.
Stack trace of thread 1615:
#0 0x000055d81bfb0223 n/a (/usr/bin/dockerd + 0x59223)
#1 0x000055d81bfb049e n/a (/usr/bin/dockerd + 0x5949e)
#2 0x000055d81bfafefc n/a (/usr/bin/dockerd + 0x58efc)
#3 0x000055d81bfafe5b n/a (/usr/bin/dockerd + 0x58e5b)
#4 0x000055d81bf9ad56 n/a (/usr/bin/dockerd + 0x43d56)
#5 0x000055d81bf9abee n/a (/usr/bin/dockerd + 0x43bee)
#6 0x000055d81bf9a213 n/a (/usr/bin/dockerd + 0x43213)
#7 0x000055d81bf967fe n/a (/usr/bin/dockerd + 0x3f7fe)
#8 0x000055d81bf970c5 n/a (/usr/bin/dockerd + 0x400c5)
#9 0x000055d81bff97a5 n/a (/usr/bin/dockerd + 0xa27a5)
#10 0x000055d81bf97bc5 n/a (/usr/bin/dockerd + 0x40bc5)
#11 0x000055d81bf7dfde n/a (/usr/bin/dockerd + 0x26fde)
#12 0x000055d81bf7da3d n/a (/usr/bin/dockerd + 0x26a3d)
#13 0x000055d81bfc6777 n/a (/usr/bin/dockerd + 0x6f777)
#14 0x000055d81c002aa0 n/a (/usr/bin/dockerd + 0xabaa0)
#15 0x00007f52122276e9 __libc_start_main (libc.so.6 + 0x276e9)
#16 0x000055d81bf7a055 n/a (/usr/bin/dockerd + 0x23055)
ELF object binary architecture: AMD x86-64
Dec 20 03:22:46 tencent systemd[1]: Starting Docker Application Container Engine...
Dec 20 03:22:46 tencent systemd[1]: docker.service: Scheduled restart job, restart counter is at 2.
排查
服务日志中的 code=dumped, status=11/SEGV 很奇怪,通常是程序中出现了内存访问错误,于是手动运行 /usr/bin/dockerd 二进制文件,发现 --help 就会直接崩溃退出:
/usr/bin/dockerd --help
# [1] 2264 segmentation fault (core dumped) /usr/bin/dockerd --help
因此推测并不是服务器上某个容器运行导致的问题,而是更靠前的 dockerd 命令初始化就有问题,那么本地刚更新的环境说不定也能复现。
在本地刚更新过的 Arch Linux 上运行相同命令,正常输出帮助信息,无法复现该问题。于是开始对比两个环境的差异,先检查二进制文件:
# 腾讯云服务器 root@tencent
ls -l /usr/bin/dockerd && sha256sum /usr/bin/dockerd
# -rwxr-xr-x 1 root root 77457360 Dec 15 02:17 /usr/bin/dockerd
# ca427bc50b1d99e376d8142abae25f7570d713c80e00c75c3d7a68fc734cdf88 /usr/bin/dockerd
# 本地主机 nian@legion
ls -l /usr/bin/dockerd && sha256sum /usr/bin/dockerd
# -rwxr-xr-x 1 root root 77457360 12月15日 02:17 /usr/bin/dockerd
# 0494c16efe5c5bd1529a3d101f17de7304765699fd0471bc73ebc822bee57ba6 /usr/bin/dockerd
两个环境的二进制文件大小一致,但计算出的 SHA256 不同,初步怀疑是服务器上的文件有问题,于是又从官方包中提取文件进行确认:
wget https://archive.archlinux.org/packages/d/docker/docker-1:29.1.3-1-x86_64.pkg.tar.zst
tar -xvf ./docker-1:29.1.3-1-x86_64.pkg.tar.zst usr/bin/dockerd --strip-components=2
ls -l ./dockerd && sha256sum ./dockerd
# -rwxr-xr-x 1 nian nian 77457360 12月15日 02:17 ./dockerd
# 0494c16efe5c5bd1529a3d101f17de7304765699fd0471bc73ebc822bee57ba6 ./dockerd
确认是服务器上的 /usr/bin/dockerd 文件损坏,尝试查找原因,于是执行 journalctl -r 查看全量系统日志,发现大量 I/O error:
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997257
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997256
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997255
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997254
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997253
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997252
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997251
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997250
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997249
Dec 20 03:22:02 tencent kernel: Buffer I/O error on device vda1, logical block 18997248
Dec 20 03:22:02 tencent kernel: EXT4-fs (vda1): failed to convert unwritten extents to written extents -- potential data loss! (inode 800622, error -5)
Dec 20 03:22:02 tencent kernel: EXT4-fs warning (device vda1): ext4_end_bio:368: I/O error 10 writing to inode 800622 starting block 18998786)
Dec 20 03:22:02 tencent kernel: I/O error, dev vda, sector 151982096 op 0x1:(WRITE) flags 0x4000 phys_seg 124 prio class 2
进一步怀疑是服务器文件系统或底层存储出现问题,写入和读取数据时有概率失败,因此尝试手动复现:
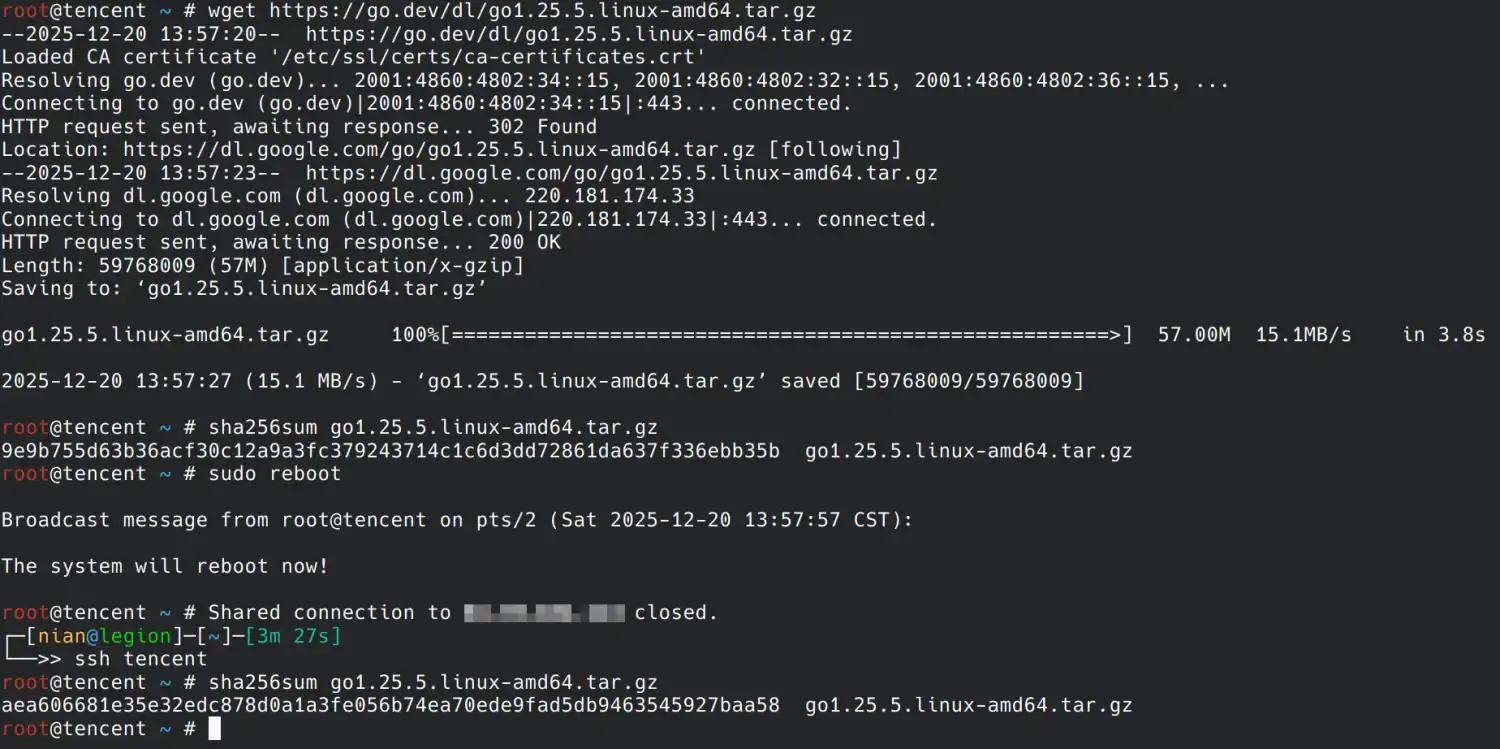
先在服务器上下载 go1.25.5.linux-amd64.tar.gz 作为示例文件,计算其 SHA256,与 Golang 官网公布的值对比确认一致。
然后重启服务器再次计算该文件的 SHA256,发现结果出现变化,在 journalctl -f 中能够观察到重启前有明显的文件写入报错:
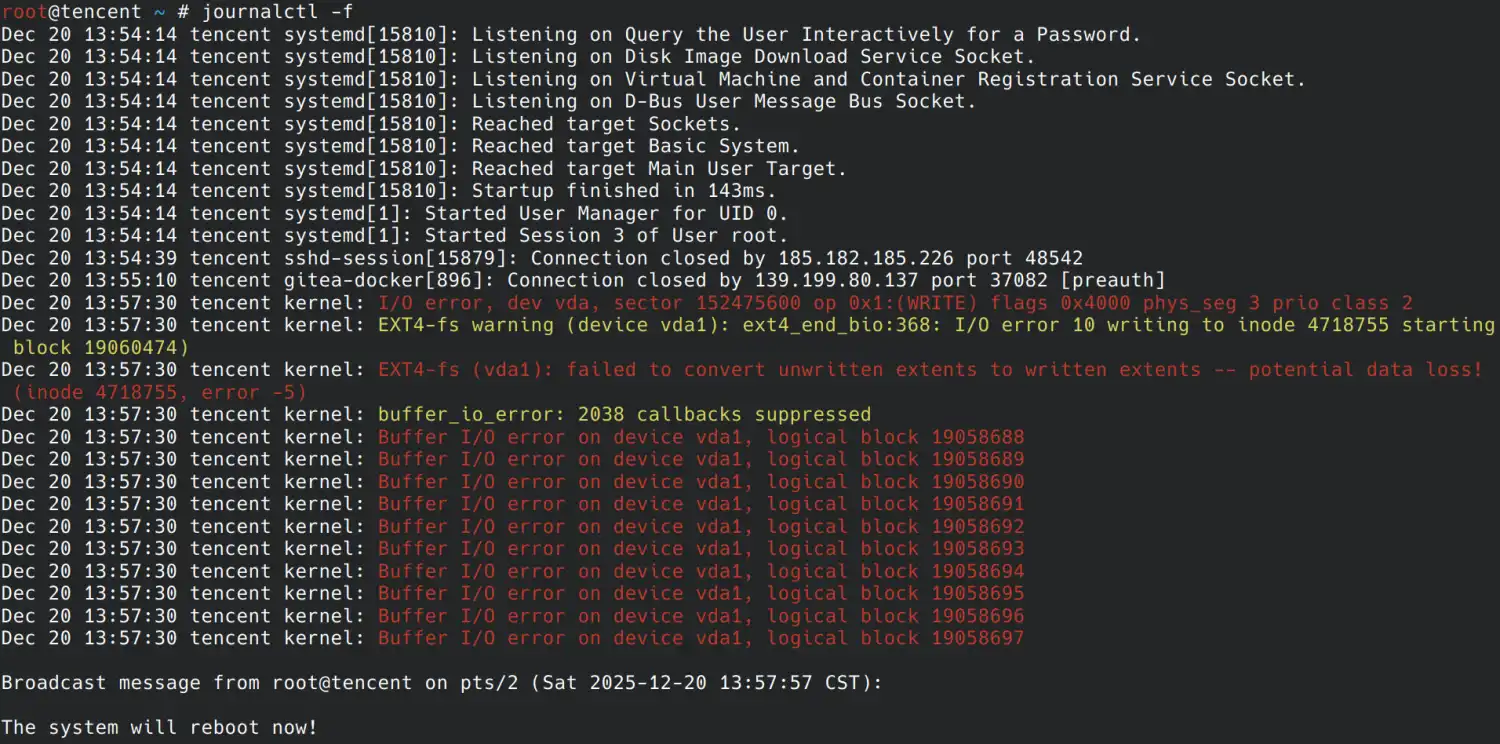
根据复现结果推测,服务器上的 ext4 文件系统正常,但底层存储存在硬件故障,写入文件时内存中的数据未能全部写入到硬盘。
因此重启前利用内存中的数据还可以计算出正确的 SHA256,但重启后从硬盘读取的数据已经损坏,计算出的 SHA256 发生变化。
尝试查找云硬盘监控及站内通知,未发现相关异常告警,自己对于可能的硬件故障无法继续排查,只能联系腾讯云客服:
- 14:43 整理问题描述及复现截图提交工单
- 14:47 客服回复开始排查
- 16:06 客服转接高级工程师
- 16:37 向用户申请 VNC 访问权限及 root 密码
- 16:58 重新发起申请后,用户完成授权
- 17:51 电话沟通说需要联系产研同事协助,询问该问题是否紧急,用户表示不紧急可以等到周一
原因
2025-12-22 周一上午 10:48 收到工单回复:
您好,查看您的内核参数
/sys/block/vda/queue/max_sectors_kb默认值改成了 4096,云上参数建议设置成 512
可以通过增加/etc/udev/rules.d/99-vda-max-sectors.rules文件的方式配置这个参数,文件内容如下
ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="vda", ATTR{queue/max_sectors_kb}="512"
按照建议创建 udev 规则文件后重启服务器,问题得到解决,无法再通过复现步骤在系统日志中观察到 I/O error。
以 max_sectors_kb 为关键词在 Google 进行搜索,发现搜索结果过于宽泛,未找到类似问题。
于是又到 GitHub 搜索 issues,发现有一个近期的问题 腾讯轻量安装rocky 9失败,其中提到是“新内核”将该参数设置为了 4096。
利用落絮搜索 Telegram 上的 #archlinux-cn 群组,在搜索结果中也可以看到相关消息:
- Sherlock Holo (2025-10-31 21:57:53):
摇到人来看了,底层存储用的 spdk,然后 /sys/block/vda/queue/max_sectors_kb 值是 4096,会导致当大包 io 过去宿主机时,spdk 那边会拒绝,底层 spdk 只支持 128 512 - Sherlock Holo (2025-10-31 22:11:11):
需要这么一条ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="vd*", DRIVERS=="virtio_blk", RUN+="/bin/sh -c 'echo 512 > /sys/$DEVPATH/queue/max_sectors_kb'"来让 udev 改掉 - Sherlock Holo (2025-11-02 00:43:07):
max_sectors_kb 参数在arch 6.17.5内核里面默认设置为了4096(4M), centos7 3.10内核则设置为512(1024个扇区,每个扇区512字节)
总结下来就是云服务器提供商的底层存储实现存在限制,不支持过大的单次 I/O 操作,而 Arch Linux 近期的内核更新导致 max_sectors_kb 参数值变为 4096,文件读写操作概率失败。
根据云服务器上的 /var/log/pacman.log 和 journalctl -r 全量系统日志,本次问题的详细发展历程为:
- 2025-10-13 01:57 执行
pacman -Syu,将 linux 内核版本从 6.16.8.arch3-1 升级到了 6.17.1.arch1-1,更新完手动重启服务器 - 2025-10-13 01:59 出现第一条报错
kernel: I/O error, dev vda, sector 17008392 op 0x0:(READ) flags 0x84700 phys_seg 3 prio class 2,之后就开始断断续续出现读写错误 - 2025-12-20 03:21 执行
pacman -Syu,升级过程中将 docker 版本从 1:29.1.1-1 升级到了 1:29.1.3-1,升级过程中出现写入错误,导致硬盘上的/usr/bin/dockerd文件损坏 - 2025-12-20 03:22 重启服务器后发现 dockerd 无法启动,开始排查该问题
根据 Arch Linux kernel Releases 可知,Arch Linux 的 kernel 主要跟随上游 stable 版本,在每个版本的基础上追加一系列 patch。在追加的 patch 中没有找到 max_sectors_kb 相关内容,因此推测是上游引入的改动,最终在 kernel 6.17 的 更新日志 中找到了相关提交 block: Increase BLK_DEF_MAX_SECTORS_CAP。
根据提交说明可知,上一次是 2015 年的改动将 max_sectors_kb 最大值从 512 增加到了 1280,这次改动是从 1280 增加到了 4096。那么 2025-10-13 系统更新前的值应该是 1280,于是手动将 /etc/udev/rules.d/99-vda-max-sectors.rules 文件中的值修改为 1280,重启服务器后也可以正常工作,无法在系统日志中复现 I/O error。
试着统计了不同环境下 max_sectors_kb 和 max_hw_sectors_kb 的值:
| environment | os | kernel | disk | max_sectors_kb | max_hw_sectors_kb |
|---|---|---|---|---|---|
| 腾讯云轻量应用服务器 | Arch Linux | 6.18.2.arch2-1 | vda (SSD 云硬盘) | 512 (已修改) | 2147483647 |
| 阿里云 ecs.c9i.xlarge | Debian 12 | 6.1.0-38-amd64 | nvme0n1 (ESSD 云盘 PL0) | 256 | 256 |
| 阿里云 ecs.c7a.large | Debian 12 | 6.1.0-37-amd64 | vda (ESSD 云盘 PL0) | 1280 | 2147483647 |
| 廉价云服务器 virmach | Arch Linux | 6.18.2.arch2-1 | vda (虚拟硬盘) | 4096 | 2147483647 |
| 廉价云服务器 racknerd | Debian 13 | 6.12.57+deb13-amd64 | vda (虚拟硬盘) | 1280 | 2147483647 |
| 本地主机 legion | Arch Linux | 6.18.2-arch2-1 | nvme0n1 (nvme 固态硬盘) | 128 | 128 |
| 本地主机 legion | Arch Linux | 6.18.2-arch2-1 | sda (sata 机械硬盘) | 4096 | 32767 |
| 本地下载机 n150 | Arch Linux | 6.18.2-arch2-1 | nvme0n1 (nvme 固态硬盘) | 512 | 512 |
| 本地下载机 n150 | Arch Linux | 6.18.2-arch2-1 | sda (sata 固态硬盘) | 4096 | 32767 |
| 本地玩具机 phicomm-n1 | Armbian 25.2.3 | 5.9.0-arm-64 | mmcblk1 (内置 emmc) | 255 | 255 |
| 本地玩具机 raspi | Debian 12 | 6.12.47+rpt-rpi-v8 | mmcblk0 (microSD 卡) | 512 | 512 |
可以看到固态硬盘倾向设置比机械硬盘更小的 max_hw_sectors_kb,物理硬盘的 max_sectors_kb 通常直接受到 max_hw_sectors_kb 限制,而云服务器上的虚拟硬盘则多数未限制 max_hw_sectors_kb,导致内核中的 max_sectors_kb 默认最大值生效。
云服务器 virmach 上的 max_sectors_kb 值在 6.18 版本的新内核下也已经增加到了 4096,但未观察到任何 I/O error,因此可认为本次问题仅出现在腾讯云轻量服务器的底层存储上,可能要等常规发行版的内核版本也升到 6.17 之后才能得到修复。
解决
虽然自测将 max_sectors_kb 设置为 1280 也有效果,但考虑之后还是以工单回复为准,创建的 udev 规则文件 /etc/udev/rules.d/99-vda-max-sectors.rules 内容如下:
ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="vda", ATTR{queue/max_sectors_kb}="512"
执行 pacman -Qkk 检查已安装包的文件完整性,发现 linux-firmware-intel 和 linux-firmware-atheros 中也有几个文件校验失败,于是执行 pacman -S docker linux-firmware-intel linux-firmware-atheros 重装相关软件包。
该云服务器上还托管有 git 仓库,但本地有较早 clone 下来的完整数据,如果服务器上相关文件出现损坏,那么后续的操作应该会有明显报错,因此无需数据校验。
该云服务器上其他的静态页面或文件托管内容近期未进行手动更新,且数据重要程度低,因此也无需数据校验。